This tutorial will show how to build your own RAG: deploy Dify + Xinference/Ollama in local server.
Check Environment
- NVIDIA Driver version >= 550
- CUDA version >= 12.4
- Docker version >= 19.03 (recommend > 25)
- Docker Compose version >= 1.28 (recommend > v2)
- NVIDIA Container Toolkit
Check Docker and Docker
# Check Docker and Docker Compose version
docker --version
docker compose version
# Check if docker is running normally
systemctl status docker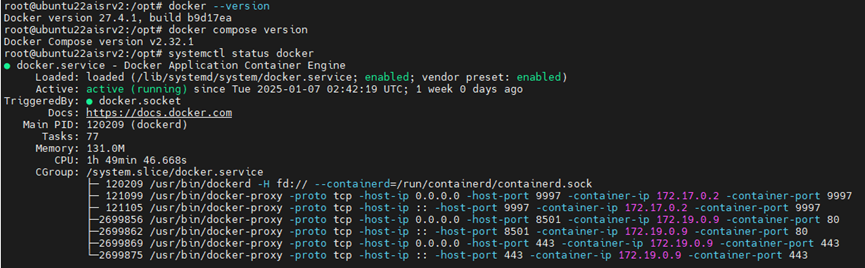
(Optional) Change root directory of Docker data
Make sure there is enough space for Docker as the you will pull images from Docker and the images size is usually large.
# Check current Docker root directory
docker info | grep "Docker Root Dir"Edit /etc/docker/daemon.json, (if not exists, then create one). Modify the data-root path then save:
# vi /etc/docker/daemon.json
{
"data-root": "/new/path/to/docker/data"
}Save and restart Docker service to reload the config:
sudo systemctl restart dockerVerify if it is effective, the output should be the path you set:
docker info | grep "Docker Root Dir"NVIDIA Container Toolkit
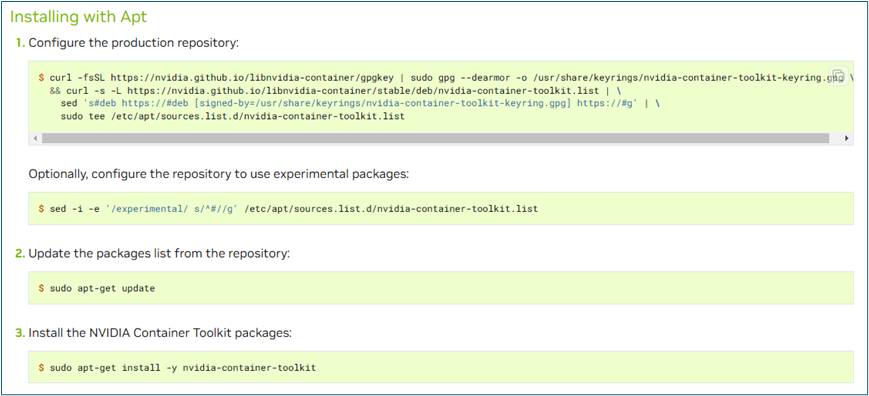
Enable Docker container to use GPU. If skip this step, you might not able to access GPU resources inside your container.
NVIDIA Installation guide could be found here.
Install and config Dify
Dify installation guide could be found here. Below I use source code from Github and Docker compose to start the services as it is the easiest way to deploy, and even upgrade in the future.
Download source code from Github, or clone the source code:
git clone https://github.com/langgenius/dify.gitGo to dify/docker, and modify the config if it needs. The environment variables explanation could be found here.
# Copy the environment config
cp .env.example .env
# Modify the config file
vi .envUsually I will change the service port instead of using the default port, and you will use this port to log in later:

Stay at dify/docker, and start Dify:
# -d means let container run in the backend
docker compose up -d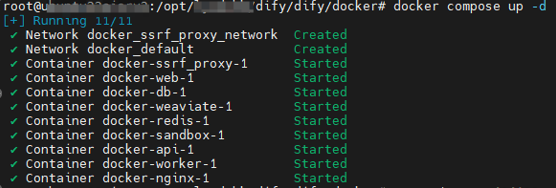
Now you can login Dify with https://ip:port. You need to set up admin account when first log in.
[OPTION 1] Install and config Xinference
Install Xinference
Official guideline could be found here. Recommend using Docker image. It is the easiest way to deploy, though it would takes some time to pull the image from dockerhub or Aliyun.

# pull image from Dockerhub
docker pull xprobe/xinference:latest
# pull image from Aliyun
docker pull registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:latestChoose the latest version should be fine. Usually I use gpu, so skip the option -cpu.
Start Xinference
Use Docker run command to start the container.
docker run -d \
-v /opt/xinference:/root/.xinference \
-v /opt/huggingface:/root/.cache/huggingface \
-v /opt/modelscope:/root/.cache/modelscope \
-p 9997:9997 \
--gpus all \
xprobe/xinference:latest \
xinference-local -H 0.0.0.0
# Param explanation
docker run \
# Run in backend
-d \
# Home path, where the logs saved
-v /your/home/path/.xinference:/root/.xinference \
# Your local model files, download from huggingface or modelscope
-v /your/huggingface/path:/root/.cache/huggingface \
-v /your/modelscope/path:/root/.cache/modelscope \
# <HostPort>:<ContainerPort>
-p 9997:9997 \
# Access all gpus, or specific one or more gpus
--gpus all \
# Docker image name and version
xprobe/xinference:v<version>\
# Can be accessed from external systems through <IP>:<PORT>
xinference-local -H 0.0.0.0
Register model
You can launch model online (it will download models directly). Or you can register your local models. Here I will show the second way.
Specifications of the models could be found here.
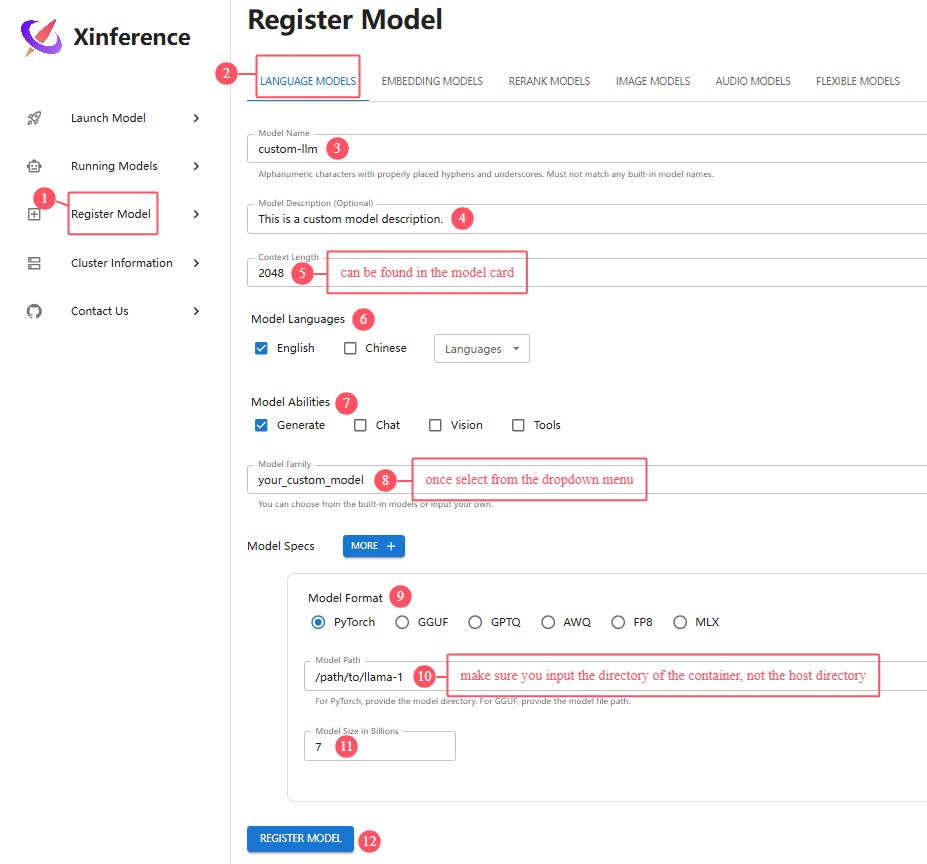
For example, I have downloaded below model files from Huggingface and uploaded to the server:
- (LLM) THUDM/glm-4-9b-chat
- (Embedding) BAAI/bge-large-zh-v1.5
- (Rerank) BAAI/bge-reranker-large
Register LLM:
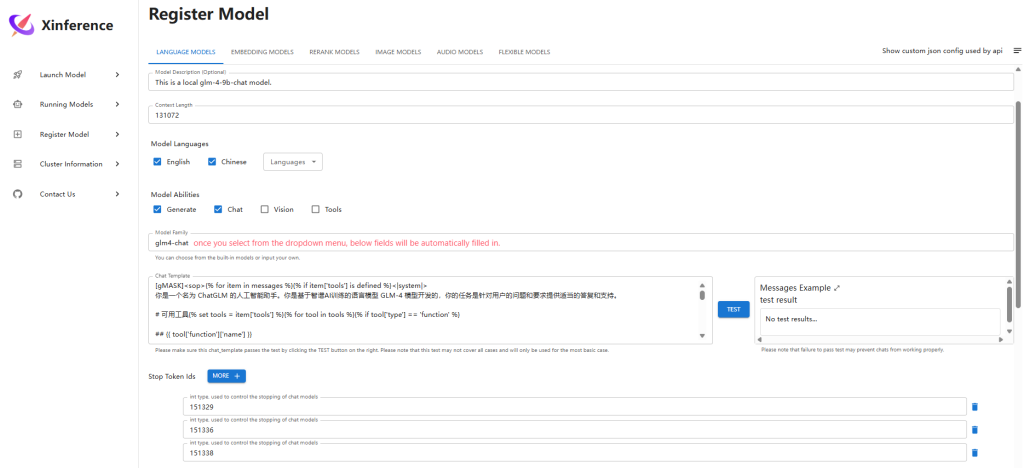
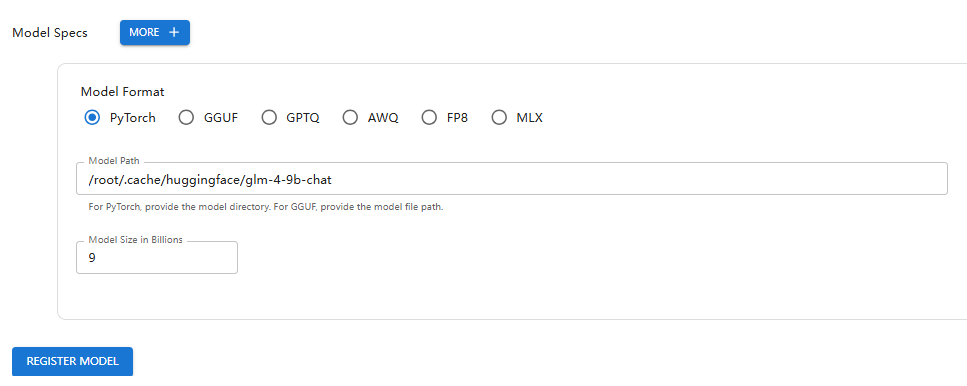
Register embedding model:
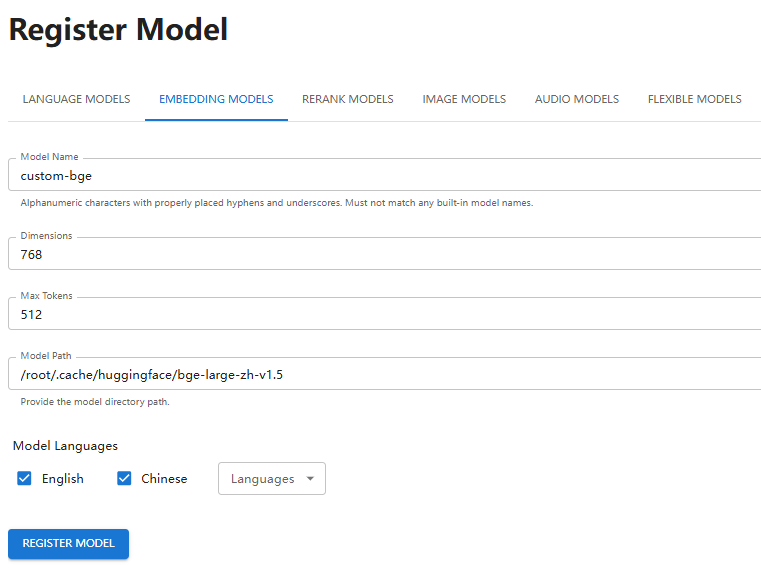
Register rerank model:
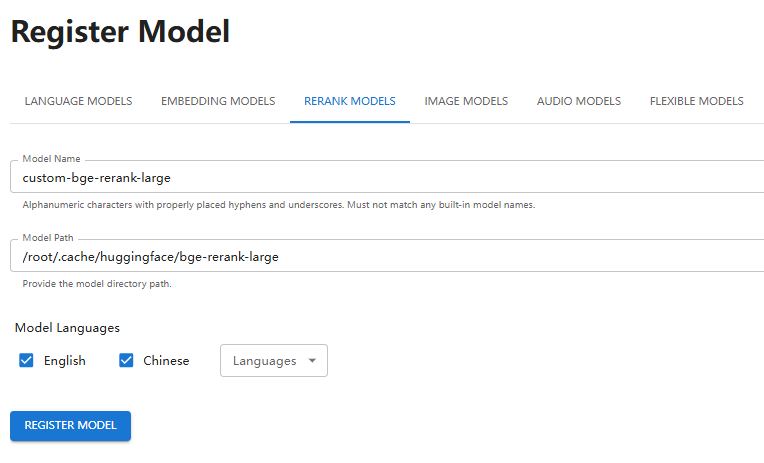
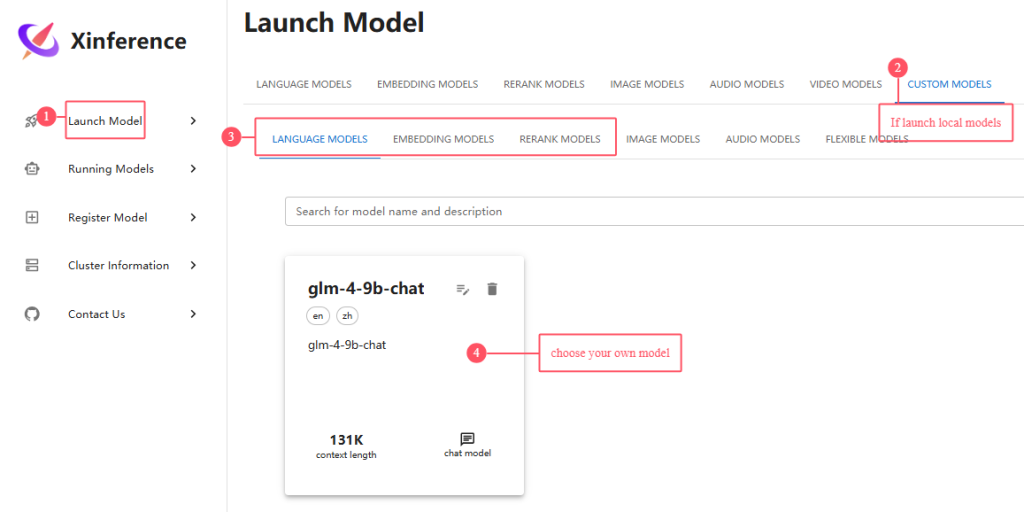
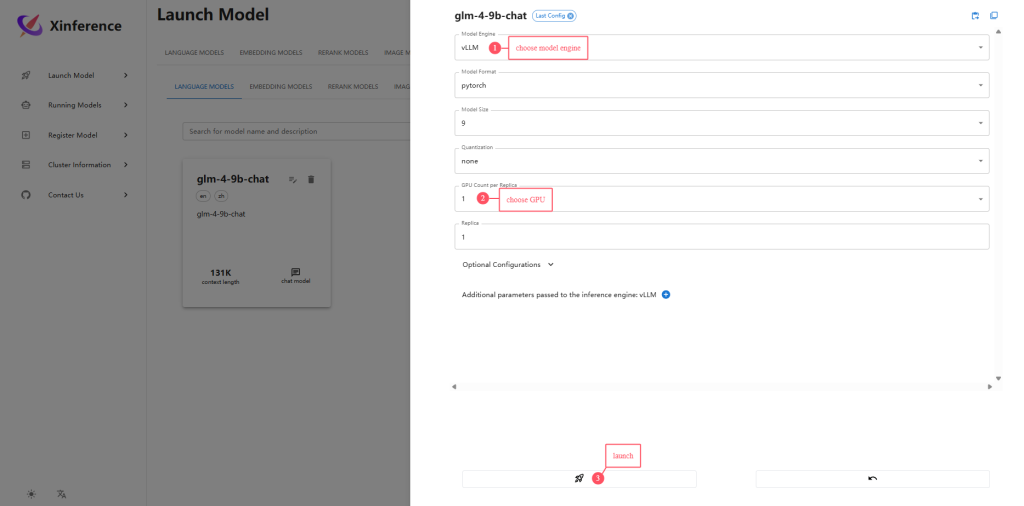
Launch model
For example, launch LLM:
[OPTION 2] Install and config Ollama
Download guideline is here.
Some frequently used command:
# run ollama in backend
ollama serve
# show model list
ollama list
# show running models
ollama ps
# pull model
ollama pull [ModelName]Integrate Xinference/Ollama in Dify
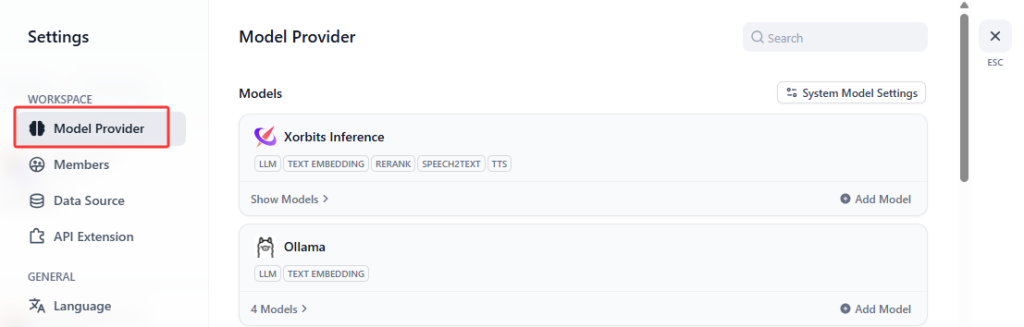
Login Dify, go to Settings – Model Provider, then install Ollama :
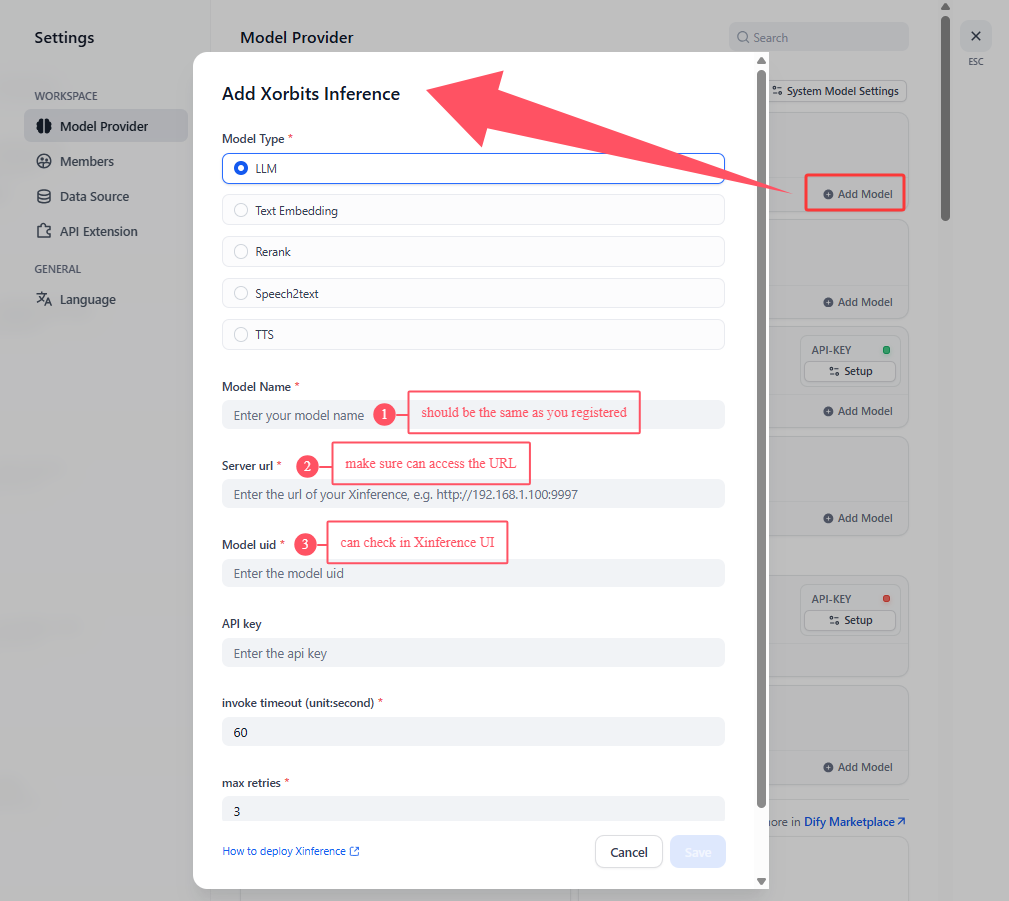
Add your model here, then able to use it in Dify workflow:
FAQ
Already installed Docker and Docker Compose, but systemctl status docker got error.
It might be due to a version mismatch between the Docker client and Docker CE.
Follow the Docker’s guideline to reinstall.
Could not find model when register model.
The model path should be the directory of your container, not the one of your host.